

What is big data?
Today, every electronic device that we use, transmits some kind of data and most of it is being collected. We generate over 2.5 Exabytes (2.5 billion Gigabytes) every single day.
In corporations, the most common types of big data collected are Log Files, Infrastructure Resource monitoring details and Spam data.
What is Big Query / Dremel / Apache Drill?
Dremel is a querying service that allows you to run SQL queries against huge datasets (think hundreds of millions of rows). It is quite simple to use and extensive development experience is not required to use it.
BigQuery (BQ) is a publicly available implementation of Dremel which is available as an IaaS (Infrastructure as a Service). It provides all the main features available via an API. The documentation of BigQuery is quite helpful as it generally provides code snippets in Java, Javascript and Python.
Apache Drill is similar to Dremel and BQ. However, it is an open source version and provides a lot of flexibility as it supports many more query languages and data formats / sources. Drill is currently incubating at Apache.
How Does it work ?
If you want to try it yourself, check out this short informative video:
http://www.youtube.com/watch?v=D-YrpJkuGqE
It is pretty easy to setup and only takes a few minutes. However, I would like to point out that you can query the preloaded data for free, but must add billing details if you want to upload data to BigQuery. Also, BigQuery doesn’t support nested datasets.
What makes BigQuery so fast?
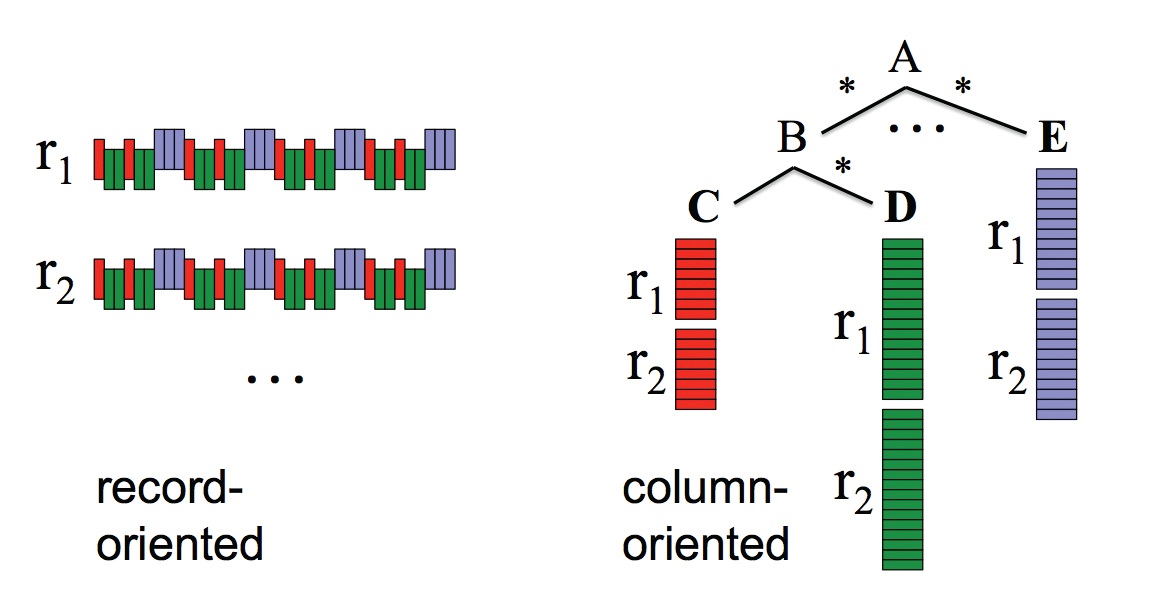
BQ can scan hundreds of millions of unindexed rows in less than a minute. There are 2 things that make BQ so fast: Columnar Storage and Tree Architecture.
1. Columnar Storage – Instead of looking at the data is terms of rows, the data is stored as columns. The advantage of this kind of columnar storage is twofold.
Firstly, only the required values are scanned. This means that only 5-20 columns need to be accessed out of the thousands available. This significantly reduces latency.
Secondly, higher compression ratios are achieved when organizing data in a columnar format. Google reports that they can achieve columnar compression ratios of 1:10 as opposed to 1:3 when storing data in a traditional row based format. The reason behind this is the similarity of data stored in the columns as the variation is significantly lower than when the data is stored in rows.
2. Tree Architecture – This is used for processing queries and aggregating results across different nodes. BQ is spread across thousands of servers. As seen in the picture above, by using a Binary Tree, the data is sharded across multiple machines. This helps retrieve data much faster. Let us see this with the help of 2 examples.
Here, A is our root server, with B being an intermediate server and C, D, E being leaf servers having local disk storage.
Example 1: Speed || Statement: List out all the customer names starting with ‘G’
Let us assume Node C contains customer names. Hence, it is as simple as traversing A -> B -> C and looking at the datasets Cr1 and Cr2 for names starting with G. One need not look at A -> B -> D and A -> E. Hence, in this simple scenario, we have already achieved a search time of 0.33x that of a typical RDBMS (assuming equal column sizes).
Example 2: Parallel Processing || Statement: Count all the customer names starting with ‘G’
- Root A passes the query to intermediate B
- B translates the query to Sum (Count all the customer names starting with ‘G’)
- Intermediate B passes this query to Leaf C
- Leaf C has tablets (Horizontal sharded tables) r1 and r2
- C accesses these tablets in parallel, runs quick counts and passes the count of Cr1 and Cr2 to B.
- B sums Cr1 and Cr2 and passes it to the root A for output.
Now, imagine if this architecture was scaled to thousands of leaf servers and hundreds of intermediate servers. This achieves enormous amounts of parallel processing by utilizing a small percentage of the CPU processing and Disk I/O of each server as opposed to 100% usage of fewer servers.
What is the difference between MapReduce and BigQuery ?

The main difference between MapReduce (MR) and BigQuery (BQ) is that MR is used to process datasets whereas BQ is used to analyze them.
MR Batch processes large datasets and can take hours or even days to do so. If a mistake is made, the process must be restarted. It is generally used for Data Mining where large unstructured datasets need to be processed programmatically. It is also needed if two large tables need to be updated or joined.
BQ queries generally finish in less than a minute. Hence, trial and error methods are possible when running queries. It is generally used for Analytical Processing / Business Intelligence where large structured CSV files are available. These can be analyzed by using simple SQL queries to filter and aggregate columns. In BQ, Only a small table can be joined with a large table in BQ, as each small table is joined with every node in the Binary Tree. Also, updating records is not possible as it is not efficient due to the many nodes and sharded tablets.
Where does PowerDrill come in ?
PowerDrill (PD) is quite similar to BigQuery, except for one main feature: It keeps frequently used data in the memory.
So when a few selected datasets (or as much of them) are cached, instead of looking at hundreds of millions of rows, we can now look at 100x the data size viz. tens of billions of rows. This is achieved by indexing the data and storing it as chunks.
- Use a Query with a Where clause to create indexes.
- The result of this query is chunked out and kept separately in the memory.
- Next time someone looks for this Where clause, it can be simply retrieved from memory instead of doing another search.
- The more the number of chunks, the faster the queries are, as compared to a RDBMS. Generally, in a RDBMS, if more than 10% of the data in a table is touched, it does a full table scan.
- This reduces the processing time from tens of seconds to a mere few seconds.
Google reports that it uses PD on 2 AdSpam datasets and a single mouse click runs more than 20 SQL queries, which process over 700 billion cells. And the results are retrieved in less than 2 seconds per query (which is 20×2 = 40 seconds overall). An average user sends out over 160 queries a day!
Summary:
- BigQuery processes huge datasets very quickly, is available as an Iaas and is free to try out.
- MapReduce is great for processing unstructured datasets but not analyzing structured datasets.
- PowerDrill keeps all possible index chunks about a few tables in memory which achieves 100x data scalability.
Sources:
https://bigquery.cloud.google.com
https://developers.google.com/bigquery/browser-tool-quickstart
https://cloud.google.com/files/BigQueryTechnicalWP.pdf
http://wiki.apache.org/incubator/DrillProposal?action=AttachFile&do=get&target=Drill+slides.pdf
http://vldb.org/pvldb/vol5/p1436_alexanderhall_vldb2012.pdf
https://www.youtube.com/playlist?list=PLOU2XLYxmsIKk5-eHOvuTwJvMkbV1DyUW
One thought on “Google BigQuery vs MapReduce vs PowerDrill”